
Machine Learning in Production - Rendezvous Architecture
04 Oct 2020Architecting a platform to enable deployments and maintenance of machine learning models is not as straightforward as conventional software architectures. The most common misconception among software developers and data scientists is that a machine learning project lifecycle consists of just training a single successful model and deploying it in a service. The real world scenario is much more complicated than this. In fact, assuming that there would always be a single model in service for a particular problem statement is fallacious.
While conventional software architectures take into account that multiple versions of services will be in-effect at any given point of time and provide processes such as blue-green or canary deployments, these processes cannot be directly imported to a Machine Learning Development Lifecycle. In this blog post, I will attempt to explore the Rendezvous Architecture, which addresses most of the problems associated with deploying machine learning models into production.
Requirements For The Architecture
1. Ability to support large number of models
Realistically, any team would be working on multiple models for the same problem statement and multiplied with the number of problem statements and the number of teams, the number of models in productions explodes to hundreds. Moreover, the same model needs to retrained daily, weekly or monthly in order to be relevant. The architecture should be able to support having hundreds of models in production at the same time.
2. Staging Environments for the models
Multiple models will be in “staging” mode that are in queue waiting to replace current models in production. How do we enable hot-swapping of models in production without affecting the performance of the service?
3. Automated Fallback
If the deployment of the new model fails, we need to have an automated fallback system in place where the model is rolled back and the older version takes over. This also applies to scenarios where the main model fails or does not respond in time in production. We should have a fallback strategy where an inferior/stable model is picked up in case the main model fails.
4. Making Room for business requirements and feature creep
We need to be able to handle feature creep. Although a particular model might be deployed to address a particular problem statement, that problem statement tends to expand rapidly due to the nature of tech business. We need to have the capability to enhance current models or deploy different models in short succession.
5. Logging
We need to build an infrastructure that captures and logs live production data that is fed as input to the models. Training new models is only effective if they’re trained on actual live data instead of a curated training set. Moreover, live inputs tend to “drift” as time passes and the current models might become obsolete sooner than you think. Logging live production data, as the current models see, is paramount in detecting drift, to train new models and to debug existing models.
6. Multi-tenancy
Multi-tenancy in machine learning. Any SaaS company will be supporting multiple clients at the same time. Expecting the data science team to train a single model that caters to all the clients is intractable. Having client specific trained models in production is a common scenario. This means that we are looking at having hundreds, if not thousands, of models in production and they should provide basic multi-tenancy capabilities such as data separation, independent model upgrades etc.
7. Monitoring
Monitoring and telemetry of the current models in production. We do not want to wait until the users start noticing the degraded model before we push out a new version.
8. Deployment Strategies
Similar to the blue-green/canary strategies in conventional service deployments, we need to have a robust strategy for model deployment as well.
Rendezvous Architecture
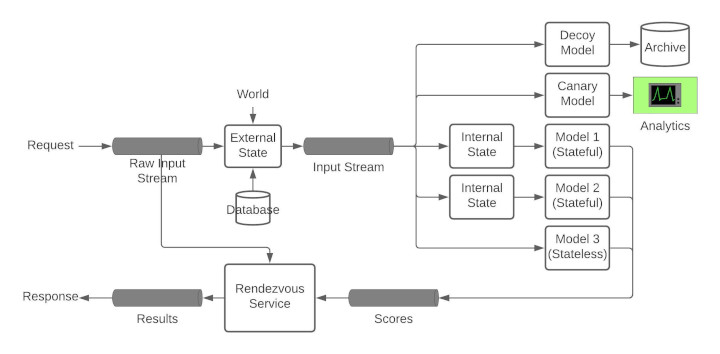
A. Overview
The first interesting thing about the Rendezvous Architect is the stream processing of the requests and responses. The advantages of a stream based architecture is the low latency, decoupling of producers and consumers and a pull-based architecture that sidesteps complicated service discovery conundrums. Moreover, using persistent streams such as Kafka also enables logging and monitoring of the input data.
The incoming request is published to an input queue (with a unique request ID) that all the models are subscribed to. The results of the models are then subsequently published to an output stream. Since there are multiple outputs (or scores for each request, how do we decide which result to send back to the client? This is where the Rendezvous Service fits in.
B. Rendezvous Service
The key component of the Rendezvous Architecture is the Rendezvous Service since this service acts as a orchestrator between all the models in production. The Rendezvous Service maintains an internal queue for each request in the request stream. As each model publishes the results to the results stream, the Rendezvous Service reads these responses and queues them in the request-specific queue. Now, Rendezvous Service needs to make a decision as to which result to be sent back to the client. This is decision making addresses most of the requirements outlined in the previous section. Based on the latencies of each model, the Rendezvous Service can change the priorities of the responses and eventually chooses one result as the response and posts it to the final results stream.
-
Staging Models: Rendezvous Service can be instructed to ignore the results of the new version and log them instead to monitor how well the new model is performing.
-
Latency Guarantees: Rendezvous Service can be configured to send whatever result is available if the main model fails to respond in time.
-
Automated Fallback: Rendezvous Service can pick the results from a baseline model if the main model fails
-
A/B Testing: Rendezvous Service can pick version A model output for certain users and version B model output for other users.
C. Stateful and Stateless Models
Models that output the same results for the same input are defined as stateless models. For example, an image recognition model always outputs the same softmax output for a particular input irrespective of when the model was run. Only a change in the model results in a change in the output.
Stateful models are models that are dependent on a particular state at the time of input. Defining this state is model dependent. For example, recommendations are stateful models. The primary input can be the input query that the user is typing in the searching box. State can the previous search history, order history, buying pattern and positive click reinforcements. The state can be internal state (user profile) or external state (geography, time-of-day etc. For example, the buying pattern in the user’s country).
The key distinction between the internal and external states is: if the state values are specific only to the particular model and the model has all access to the desired state and/or can compute these state values at run-time, then this state is called as internal state. State values that are common to all models or values that are not accessible to the models themselves constitute external state.
In Rendezvous Architecture, external states must be injected into the input before being fed into any model. External states must be injected in the pipeline before feeding it to the models so that all models receive the exact same input for reproducibility purposes.
Internal states can be injected right before feeding to the particular model.
D. Decoy Models
Logging live production data, as the input models see, is critical as outlined in the Requirements section above. The simplest way to ensure that we are seeing what the models are seeing is to deploy a decoy model at the same hierarchy as other models that does nothing other than logging the inputs. This is extra critical in case of stateful models where the state is injected at real-time.
E. Canary Models
Canary models are baseline models that are deployed to analyse the input data and is used to detect drift in the input data and to provide a baseline benchmark to the other models in production.
F. Containerize
“But, it works on my system!” is no longer an excuse for software engineers. Same holds true for data scientists as well. Debugging different results on the production and development environments is complicated. Moreover, every container can come pre-built with necessary scaffolding required for operations, monitoring, logging, security etc. Hence, every single component in the Rendezvous Architecture must be containerized.
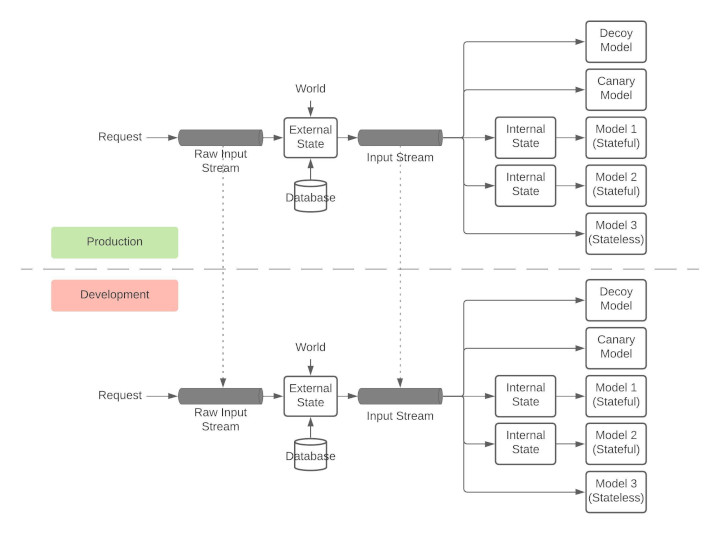
G. Replication for Development
The development environments must be as close to the production environment as possible. This can be achieved through stream replication.
H. Monitoring
Rendezvous Architecture enables multiple types of monitoring
- Model Monitoring: Monitoring of the performance of the models themselves such as accuracy, F1 scores etc
- Data Monitoring: Data monitoring looks at the input data and the output data and ensures that there is no drift.
- Operations Monitoring: Assuming the models are performing as expected, operations monitoring focuses on the services themselves. This involves latencies, concurrent requests etc. This monitoring does not involve looking into the data being passed between the services.
Pitfalls of Rendezvous Architecture
Rendezvous Architecture assumes that every model runs in isolation (i.e) no model is dependent on any other model. If this assumption breaks down and data coupling between models occur, then Rendezvous Architecture does not have a straightforward solution. Such situations must be avoided as much as possible and if they do occur, careful attention must be bestowed while upgrading/retiring these models.