04 Oct 2020
Architecting a platform to enable deployments and maintenance of machine learning models is not as straightforward as conventional software architectures. The most common misconception among software developers and data scientists is that a machine learning project lifecycle consists of just training a single successful model and deploying it in a service. The real world scenario is much more complicated than this. In fact, assuming that there would always be a single model in service for a particular problem statement is fallacious.
While conventional software architectures take into account that multiple versions of services will be in-effect at any given point of time and provide processes such as blue-green or canary deployments, these processes cannot be directly imported to a Machine Learning Development Lifecycle. In this blog post, I will attempt to explore the Rendezvous Architecture, which addresses most of the problems associated with deploying machine learning models into production.
Requirements For The Architecture
1. Ability to support large number of models
Realistically, any team would be working on multiple models for the same problem statement and multiplied with the number of problem statements and the number of teams, the number of models in productions explodes to hundreds. Moreover, the same model needs to retrained daily, weekly or monthly in order to be relevant. The architecture should be able to support having hundreds of models in production at the same time.
2. Staging Environments for the models
Multiple models will be in “staging” mode that are in queue waiting to replace current models in production. How do we enable hot-swapping of models in production without affecting the performance of the service?
3. Automated Fallback
If the deployment of the new model fails, we need to have an automated fallback system in place where the model is rolled back and the older version takes over. This also applies to scenarios where the main model fails or does not respond in time in production. We should have a fallback strategy where an inferior/stable model is picked up in case the main model fails.
4. Making Room for business requirements and feature creep
We need to be able to handle feature creep. Although a particular model might be deployed to address a particular problem statement, that problem statement tends to expand rapidly due to the nature of tech business. We need to have the capability to enhance current models or deploy different models in short succession.
5. Logging
We need to build an infrastructure that captures and logs live production data that is fed as input to the models. Training new models is only effective if they’re trained on actual live data instead of a curated training set. Moreover, live inputs tend to “drift” as time passes and the current models might become obsolete sooner than you think. Logging live production data, as the current models see, is paramount in detecting drift, to train new models and to debug existing models.
6. Multi-tenancy
Multi-tenancy in machine learning. Any SaaS company will be supporting multiple clients at the same time. Expecting the data science team to train a single model that caters to all the clients is intractable. Having client specific trained models in production is a common scenario. This means that we are looking at having hundreds, if not thousands, of models in production and they should provide basic multi-tenancy capabilities such as data separation, independent model upgrades etc.
7. Monitoring
Monitoring and telemetry of the current models in production. We do not want to wait until the users start noticing the degraded model before we push out a new version.
8. Deployment Strategies
Similar to the blue-green/canary strategies in conventional service deployments, we need to have a robust strategy for model deployment as well.
Rendezvous Architecture
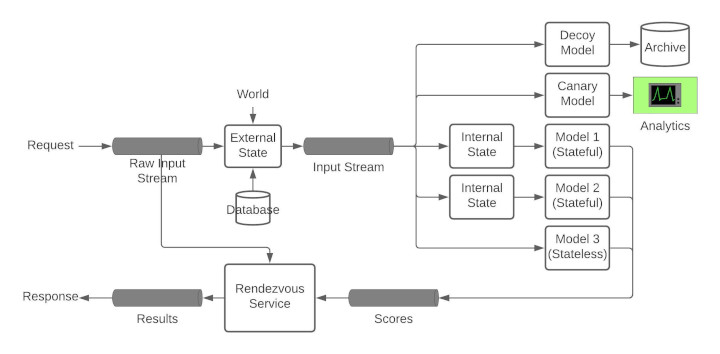
A. Overview
The first interesting thing about the Rendezvous Architect is the stream processing of the requests and responses. The advantages of a stream based architecture is the low latency, decoupling of producers and consumers and a pull-based architecture that sidesteps complicated service discovery conundrums. Moreover, using persistent streams such as Kafka also enables logging and monitoring of the input data.
The incoming request is published to an input queue (with a unique request ID) that all the models are subscribed to. The results of the models are then subsequently published to an output stream. Since there are multiple outputs (or scores for each request, how do we decide which result to send back to the client? This is where the Rendezvous Service fits in.
B. Rendezvous Service
The key component of the Rendezvous Architecture is the Rendezvous Service since this service acts as a orchestrator between all the models in production. The Rendezvous Service maintains an internal queue for each request in the request stream. As each model publishes the results to the results stream, the Rendezvous Service reads these responses and queues them in the request-specific queue. Now, Rendezvous Service needs to make a decision as to which result to be sent back to the client. This is decision making addresses most of the requirements outlined in the previous section. Based on the latencies of each model, the Rendezvous Service can change the priorities of the responses and eventually chooses one result as the response and posts it to the final results stream.
-
Staging Models: Rendezvous Service can be instructed to ignore the results of the new version and log them instead to monitor how well the new model is performing.
-
Latency Guarantees: Rendezvous Service can be configured to send whatever result is available if the main model fails to respond in time.
-
Automated Fallback: Rendezvous Service can pick the results from a baseline model if the main model fails
-
A/B Testing: Rendezvous Service can pick version A model output for certain users and version B model output for other users.
C. Stateful and Stateless Models
Models that output the same results for the same input are defined as stateless models. For example, an image recognition model always outputs the same softmax output for a particular input irrespective of when the model was run. Only a change in the model results in a change in the output.
Stateful models are models that are dependent on a particular state at the time of input. Defining this state is model dependent. For example, recommendations are stateful models. The primary input can be the input query that the user is typing in the searching box. State can the previous search history, order history, buying pattern and positive click reinforcements. The state can be internal state (user profile) or external state (geography, time-of-day etc. For example, the buying pattern in the user’s country).
The key distinction between the internal and external states is: if the state values are specific only to the particular model and the model has all access to the desired state and/or can compute these state values at run-time, then this state is called as internal state. State values that are common to all models or values that are not accessible to the models themselves constitute external state.
In Rendezvous Architecture, external states must be injected into the input before being fed into any model. External states must be injected in the pipeline before feeding it to the models so that all models receive the exact same input for reproducibility purposes.
Internal states can be injected right before feeding to the particular model.
D. Decoy Models
Logging live production data, as the input models see, is critical as outlined in the Requirements section above. The simplest way to ensure that we are seeing what the models are seeing is to deploy a decoy model at the same hierarchy as other models that does nothing other than logging the inputs. This is extra critical in case of stateful models where the state is injected at real-time.
E. Canary Models
Canary models are baseline models that are deployed to analyse the input data and is used to detect drift in the input data and to provide a baseline benchmark to the other models in production.
F. Containerize
“But, it works on my system!” is no longer an excuse for software engineers. Same holds true for data scientists as well. Debugging different results on the production and development environments is complicated. Moreover, every container can come pre-built with necessary scaffolding required for operations, monitoring, logging, security etc. Hence, every single component in the Rendezvous Architecture must be containerized.
G. Replication for Development
The development environments must be as close to the production environment as possible. This can be achieved through stream replication.
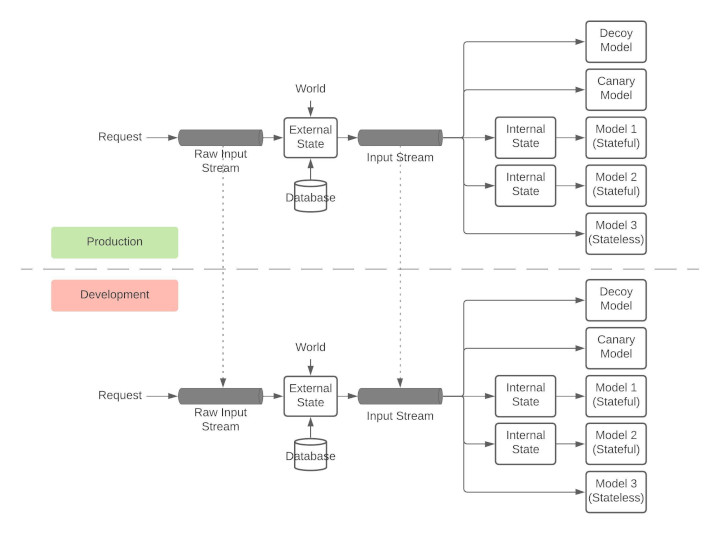
H. Monitoring
Rendezvous Architecture enables multiple types of monitoring
- Model Monitoring: Monitoring of the performance of the models themselves such as accuracy, F1 scores etc
- Data Monitoring: Data monitoring looks at the input data and the output data and ensures that there is no drift.
- Operations Monitoring: Assuming the models are performing as expected, operations monitoring focuses on the services themselves. This involves latencies, concurrent requests etc. This monitoring does not involve looking into the data being passed between the services.
Pitfalls of Rendezvous Architecture
Rendezvous Architecture assumes that every model runs in isolation (i.e) no model is dependent on any other model. If this assumption breaks down and data coupling between models occur, then Rendezvous Architecture does not have a straightforward solution. Such situations must be avoided as much as possible and if they do occur, careful attention must be bestowed while upgrading/retiring these models.
References
Machine Learning Logistics by Ted Dunning, Ellen Friedman
02 May 2020
One of the main drawbacks of any NLU neural model is it’s lack of generalization. This topic has been explored extensively in the previous post Empirical Evaluation of Current Natural Language Understanding (NLU). To what can we attribute this lack of common-sense to?
The main reason for this brittleness is the fundamental lack of understanding that a model can gain from processing just text, irrespective of the amount of text it sees. For example, it is common-sense that keeping a closet door open is ok while keeping a refrigerator door open is not good. As humans, we can reason that keeping the refrigerator door open leads to spoiling of food inside since it is perishable while clothes are non-perishable and hence it is ok to keep the closet door open. But, this information is not usually written down anywhere and hence, it is difficult for a model to learn this reasoning.
Also, text is just one modal of information that humans interact with. Humans interact with the world through sight, smell and touch and this information is inherent in understanding. The NLU models lack this crucial exposure to other modalities (which form the root of common-sense). For example, we do not write down obvious things like the color of an elephant. Written text usually talk about elephants in terms of size, like “big elephant with huge tuskers charged at the man”, while “dark grey elephant was spotted in Africa” is practically non-existent. Nevertheless, since we are exposed to pictures of elephants, we know that elephants are usually dark grey in color. If a pre-trained model is asked to predict the color of an elephant, it will fail or might even say it is white since “white elephant” is a valid phrase that is used as a metaphor.
Another reason for lacking common-sense is that common-sense is just not written down. Consider the following example:
S: The toy did not fit in the bag because it was too big.
Q: What does “it” refer to?
A: Toy
S: The toy did not fit in the bag because it was too small.
Q: What does “it” refer to?
A: Bag
In brief, why do models lack common-sense?
- There is inherent bias when humans write things down. We do not tend to write down obvious things.
- Common-sense is also not written down
- The models are not exposed to other modalities (like images, audio or video).
Incorporating common-sense into neural models:
- Build a knowledge base, similar to WordNet. We can store specific common-sense information in this database. For example, an
Elephant object can have the attribute color: grey.
- Multi-modal learning: Sun et al. VideoBERT
- Human-in-the-loop training.
Resources for common-sense reasoning
- Yejin Choi: Key researcher in the field of common reasoning. Talk at NeurIPS 2019 LIRE workshop
- Maarten Sap et al., ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning
- Antoine Bosselut et al., COMET: Commonsense Transformers for Automatic Knowledge Graph Construction
- Keisuke Sakaguchi et al., WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Datasets
- Winograd
- Winogrande (AAAI 2020)
- Physical IQA (AAAI 2020)
- Social IQA (EMNLP 2019)
- Cosmos QA (EMNLP 2019)
- VCR: Visual Commonsense Reasoning (CVPR 2019)
- Abductive Commonsense Reasoning (ICLR 2020)
- TimeTravel: Counterfactual Reasoning (EMNLP 2019)
- HellaSwag: Commonsense NLI (ACL 2019)
01 May 2020
Evaluating language understanding is as difficult as elucidating the meaning of the word “understanding” itself. Before getting into evaluating computer models on language understanding, let’s explore how we evaluate human “understanding” of natural language. How do we evaluate whether a person understands a particular language? Do we emphasize on the person’s memory of the meanings of different words? Or do we emphasize on the person’s ability to construct sequences of words/tokens that make sense to another human? Or is the ability of a person to read a passage and be able to answer questions on that passage considered to be a good indicator of his/her “understanding” of a language?
It is apparent that trying to quantify a person’s language understanding is a non-trivial pursuit. But, we have tried to quantify it nonetheless with multiple language proficiency tests across the world. The tests generally evaluate on multiple proxies (like sentence completions, fill-in-the-missing-word, passage question answering, essay writing) and the proficiency of a person is evaluated on how well he/she performs on ALL of these tasks. Important point to note here is that excelling on one section (task) and failing in another, points to a failure in language understanding.
We can draw similarity between the language proficiency tests and the natural language understanding evaluation in NLP. There are multiple datasets and benchmarks that are a proxy to the sections in tests. For example, we have the SQuaD (for passage question answering), GLUE (for next sentence predictions) etc.
Similar to the proficiency tests, we can consider a model to “understand” a language when it performs reasonably well across all the benchmarks without special training. We have seen multiple models achieving SOTA on individual benchmarks (surpassing human-levels). Does this mean we have achieved language understanding in computers? There are multiple ways we can evaluate generalizing capacity of any model. We have multiple datasets for the same task but on different domains, like having question answering datasets over multiple domains and multiple languages and any model is expected to perform well on all of them to prove understanding. While recent language models, trained on huge datasets, generalize well over multiple tasks, they still require significant fine-tuning to perform well in these tasks. There are questions raised as to whether this fine-tuning just overfits to the quirks of the individual benchmarks. Another approach is to train a model on ALL of these tasks simultaneously, proposed by McCann et al. The Natural Language Decathlon: Multitask Learning as Question Answering. They propose converting all tasks (summarization, translation, sentiment analysis etc) into a question answering problem.
This blog post covers the current state of natural language understanding and explores where/if we are lacking and is a review of the Dani Yogatama et al. Learning and Evaluating General Linguistic Intelligence.
In order to claim language understanding, a model must be evaluated on it’s abilities to
- Deal with the full complexity of natural language across a variety of tasks.
- Effectively store and reuse representations, combinatorial modules (e.g, which compose words into representations of phrases, sentences,and documents), and previously acquired linguistic knowledge to avoid catastrophic forgetting.
- Adapt to new linguistic tasks in new environments with little experience (i.e., robustness to domain shifts)
Dani Yogatam et al., evaluate BERT (based on Transformer) and ELMo (based on recurrent networks) on their general lingustic understanding. The main categories of tasks evaluated against are:
-
Reading Comprehension: This is a question answering dataset. We have 3 datasets, SQuaD (constructed from Wikipedia), TriviaQA (written by trivia enthusiasts) and QuAC (where a student asks questions about a Wikipedia article and a teacher answers with a short excerpt from the article). These are the same tasks but with different domains and distributions
-
Natural Language Inference: This is a sentence pair classification problem. Given two sentences, we need to predict whether the two sentences ENTAIL, CONTRADICT, NEUTRAL each other. We have two variants of this task: MNLI (Multi Genre Natural Language Inference) and SNLI (Stanford Natural Language Inference)
Results from Dani Yogatama et al.:
-
On both SQuAD and MNLI, both models are able to approach their asymptotic errors after seeing approximately 40,000 training examples, a surprisingly high number of examples for models that rely on pretrained module: We still need significant amount of training examples to perform well on a tasks even if the model is pretrained.
-
Jointly training BERT on SQuAD and TriviaQA slightly improves final performance. The results show that pretraining on other datasets and tasks slightly improve performance in terms of final exact match and F1 score: If you want your model to perform well on multiple domains with the same task, it is better to jointly train the model on both datasets.
-
Our next set of experiments is to analyze generalization properties of existing models. We investigate whether our models overfit to a specific dataset (i.e., solving the dataset) it is trained on or whether they are able to learn general representations and modules (i.e., solving the task). We see that high-performing SQuAD models do not perform well on other datasets without being provided with training examples from these datasets. These results are not surprising since the examples come from different distributions, but they do highlight the fact that there is a substantial gap between learning a task and learning a dataset: Just training these models on one dataset and expecting it to perform well on another dataset will not work. However, jointly training it on both datasets provide good results as mentioned in the previous point.
-
Catastrophic Forgetting; An important characteristic of general linguistic intelligence models is the ability to store and reuse linguistic knowledge throughout their lifetime and avoid catastrophic forgetting. First,we consider a continual learning setup, where we train our best SQuAD-trained BERT and ELMo on a new task, TriviaQA or MNLI. the performance on both models onthe first supervised task they are trained on (SQuAD) rapidly degrades.: Taking a SOTA model from one task, training it on another task will degrade it’s performance in the first task. This indicates that the model parameter updates from the second task is not compatible with the pre-trained model parameters for the first task. The model tends to forget what is has been trained for in the first place. This indicates that the model hasn’t achieved generalized language understanding and has merely fit to the task (and dataset) it has trained on.
tl;dr We still have a long way to reach generalized language understanding in computers even though we are achieving SOTA in each task.
24 Apr 2020
The size of the SOTA neural networks is growing bigger everyday. Most of the SOTA models have parameters in excess of 1 billion.
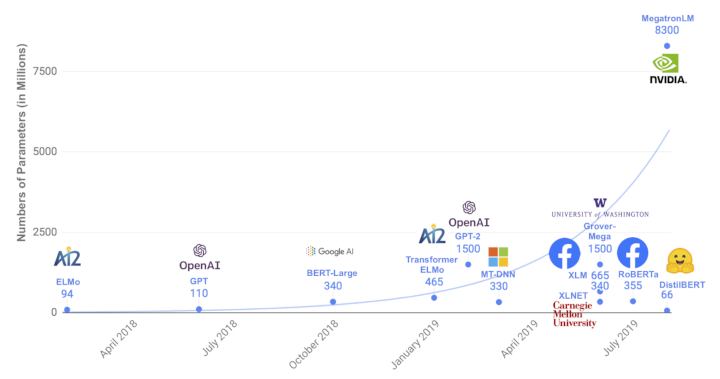
The above image is taken from Huggingface’s DistilBERT
This trend has multiple effects on NLP research:
1. NLP leaderboards are dominated by results from industry, who have access to the vast compute and data resources required to train these humongous models. Companies are incentivized to keep this research proprietary, at least part of it to maintain intellectual superiority among competitors. Open research from the academia is unable to keep up.
2. Larger model sizes preclude deploying on mobile devices.
Given these issues, this blog post summarizes the current efforts and research in the direction of reducing model footprints.
1. Neural Networks are over-parameterized
Ramanujan, Vivek et al. “What’s Hidden in a Randomly Weighted Neural Network?” proposes that even before train a neural network, a randomly initialized neural network already consists of sub-networks that can perform almost as well as a fully trained model. They also propose an algorithm to identify these sub-networks.
2. Distillation
This is a teacher-student architecture, where a bigger model (teacher)’s outputs/hidden activations are used to train a smaller model (student). This has been applied generally to many neural models. For BERT specifically, Huggingface’s DistilBERT, is a good resource with implementation. The output of the bigger BERT model and the output of the smaller model are used to calculate the cross-entropy loss (with or wothout temperature).
SOTA in distillation is TinyBERT. They propose a novel distillation procedure optimised for transformer based networks (which BERT is). Unlike DistilBERT, where only the softmax output is used to train the student, TinyBERT uses the hidden activations including the attention weight matrices to train the student.
3. Pruning
Here, we focus on reducing the model size by either removing transformer heads, weights themselves or by removing layers.
Elena Voita et al. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned propose removing the attentions heads from the transformer. Similar efforts is proposed by Paul Michel et al. in Are Sixteen Heads Really Better than One?. They propose a Head Importance Score (a differentiation of loss w.r.t the head activation) as a measure to prune heads. Results suggest that we can remove almost 60-80% of the heads without much impact on the performance.
Ziheng Wang et al. Structured Pruning of Large Language Models propose a way to remove model weights.
Angela Fan et al. Reducing Transformer Depth on Demand with Structured Dropout propose a way to remove model layers by using a method similar to dropouts. Unlike dropouts, where certain model parameters are frozen during training, they propose freezing certain layers while training. This lends the model to having some layers to be able to be removed and not affect the performance significantly.
4. Quantization
Another approach to reduction in model sizes is to convert the floating point numbers representing the model parameters into integers. Intel’s Q8BERT is one of the implementations of this approach.
