23 Feb 2017
There has been many works published in the academia that prove that a neural network has a higher capability of capturing the underlying pattern much more effectively than statistical models. This fact is embraced by the industry as well where more and more applications leverage the use of Neural Networks.
I am not going to reiterate on the various reasons why a Neural Network is better than statistical models, as I would not be able to do justice to that. I am going to demonstrate using a simple model how a neural network outperforms statistical model.
I recently came across a very simple problem on Kaggle, the Kobe's Shot Selection -
Kobe Bryant Shot Selection. It is one of the simplest problem for any beginner data scientist to cut his teeth on.
I went through a lot of solutions for this problem, which were unsurprisingly filled with Random Forests and XGBoost Classifiers. This was as expected, as XGBoost models are a proven winner in a 70% of Kaggle competitions and also, a Decision Tree would be the most intuitive model to model this particular problem.
I tried many variations of the same and was able to climb upto rank 240 using the XGBoost models. But these models relied heavily on extensive feature engineering. Me, personally, being from a non sports background, it was rather difficult to identify these features which would be relevant to the problem. I had to read blogs and other solutions to understand that certain features like "Is it the last 5 mins of the game?" or "Is it a home or away match?", are very important in order to predict the outcome. This requirement of domain knowledge is a shot in the knee for someone with limited domain knowledge.
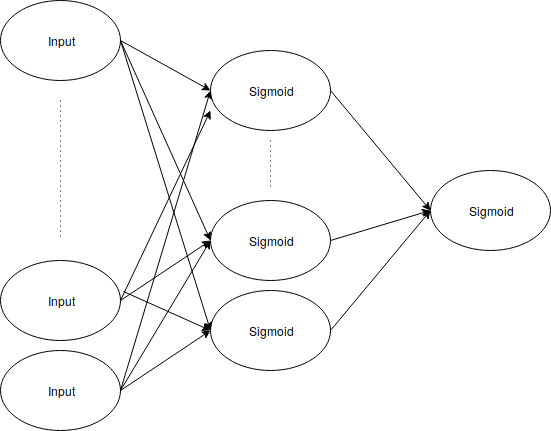
The next model I built, was a simple Feed Forward Neural Network with one hidden layer. The input dimension was 197, the hidden layer dimension was 30 and the output was a single sigmoid neuron, optimizing on binary cross entropy.

Such a simple model with practically no feature engineering at all was able to put me in the 25th position on the public leaderboard,
Public Leaderboard Ranking.
This leads me to one of the main advantages of neural networks over statistical models. You do not need any domain knowledge in order to build a model. Although the winning solution implements an XGBoost model, I am sure it involves a lot of feature engineering, which is a time consuming task.
Some of the points to keep in mind while building a neural network are:
- Always normalize the inputs. Neural Networks are optimized for working on numbers between 0 and 1. Any number greater than 1 leads to explosive gradient descent, which involves weight updates by large numbers.
- The number of parameters of the model should be significantly less than the number of training examples. If it is greater, it will lead to over fitting.
- Use neurons which align to the objective of the problem. For example, in this case, the model was being evaluated on the logloss and hence it makes sense to use sigmoid neurons.
19 Feb 2017
The objective of this post is to list down some of the pointers to keep in mind while building a Machine Learning model.
- Always start with the simplest of models. You can increase the complexity if the performance of a simple model is inadequate.
- Understand your dataset first.
- Build a baseline model before building any prediction model. I will expand on this further in another post.
- Complex models tend to over fit and simpler models tend to under fit. It is your job to find a balance between these two.
- High bias and low variance - A property of simpler models. Suggests under fitting.
- High variance and low bias - A property of complex models. Suggests over fitting.
- In any Machine Learning model, if the number of parameters is greater than the number of training examples, beware. It leads to over fitting. Try considering a simpler model with lesser number of parameters or reduce the number of hidden layers or anything else to reduce the number of parameters of the model.
- Always normalize the inputs. Neural Networks are optimized for working on numbers between 0 and 1. Any number greater than 1 leads to explosive gradient descent, which involves weight updates by large numbers.
- Regularization is very very important. Therefore, consider using an XGBoost model instead of Random Forest.
Some terms to keep in mind:
- Stratified Sampling - When the training data is overly skewed, the practice of picking the samples such the final training data has the distribution you need.
- Bootstrapping - Evaluating the same model with different random seeds.
18 Feb 2017
"Machine Learning" as a term has gained such traction in the technology world today that it is highly improbable that you would meet a person who hasn't heard this term, either in a positive or a negative connotation.
We have industry experts, CS professionals, hiring experts and practically every other person directly or indirectly related to the Computer Science domain, harping about how ML/AI is going to be the future of computing.
I am here to just explore how this came out to be, and also why I think although assuming that ML is going to be
THE future of computing might be over exaggeration, it is going to play an important role in the future nonetheless.
Where did ML start?
It might be surprising to know for a majority of you that one of the corner stones of ML, the humble Naive Bayes classifier has been around for more than 2 centuries. The Bayes theory was first published in the second half of the 18th century.
One of the cutting edge of ML research and applications, the Neural Networks has been around since the 1950s! Some of you might even be surprised to learn that this was even before the von Neumann architecture was introduced! For those of you who might not know what von Neumann architecture is, it is the basic architecture on which
ALL the computers till date were ever built.
How did ML/AI become such a rage in the latter half of this decade?
So why did it peak in the last 5 years that didn't happen in the past half a century? The answer lies in
DATA!
The success of any ML model solely depends on the type, amount and quality of data fed to the model for training. The reason why it was abandoned was because of the data. There was never enough data to train even a simple naive Bayes model. With the advent of the World Wide Web in the 2000s, although there was a lot of data being generated, the quality was still too bad to be of any use for any modelling. With the advent of iPhone and personal computers and the penetration of these personal computing devices made sure that there was no dearth in the production of data. Hence, applications of models came to the fore.
With data being produced at an unprecedented rate which might even surpass the consumption rate, these ML and AI based applications become ever more relevant to our day to day lives.
How is ML affecting our society and employment?
Nowadays we are observing a deep uncertainty over the implications of a machine capable of making decisions based on incomplete data available and its potential to disrupt the human society as a whole, with some even suggesting that the Terminator-esque scenario where the human race is hunted by the machines will come to fruition in the near future. I personally believe that such predictions are completely unfounded for various reasons. The popular media has the ability to attach negative connotation to any subject that might be hard to comprehend. If you look at the world today, we can already see a vast majority of our lives being penetrated by ML or AI, without us noticing at all. That Google search you just did to find out how the weather would be today, or your Facebook or Instagram feed, were all powered by ML.
A couple of decades ago, blue collar factory workers were looked up to as they were considered skilled employees. Youth were drawn towards the glamourous appeal of urban and factory life compared to the agricultural livelihood, as can be seen from the mass migration of rural youth to urban centres which were primarily built around factories. But in the last decade, most of these blue collar jobs were replaced by automated machines, which were both reliable and efficient. Although there were large scale protests against the loss of jobs, the society did not complain when the prices of their day to day products went down and the quality increased. The job market corrected itself after the people who lost their jobs were able to find other means of livelihood made possible by the booming economy brought about by the reduction in production costs.
Similarly, the society is unsettled with the advent of self driving vehicles, personal assistants etc and its potential to cut human jobs and increase the chances of machines taking over the world. But if we look around us, ML has already taken over our lives and the market has always self corrected itself after a short term decrease in employment.
In the long term, the ability of a machine to take over mind numbing and routine tasks opens up other avenues for human kind. We can now explore the more creative and intellectually stimulating pursuits that we couldn't afford before. By assigning all the manual and dirty work to the machines, we are actually left free to advance mankind in a more creative venture. This is analogous to getting a maid at home. Whether we will utilize the new found freedom to advance mankind or to other self destructing avenues remain to be seen. But one thing is for certain, if the society does enter an apocalyptic phase, it is only us to be blamed and not the ML/AI.
Where is ML headed?
In the near future, software development in services is headed towards the same path as the blue collar factory jobs of yesteryears. Since most of the basic architectures and systems are already in place, majority of the software servicing roles have become repetitious. As history as shown us, these repetitious and monotonous jobs are going to be automated with new jobs being created for more intellectually challenging and creative ventures. This is not to say that the entire software development industry is going to be shut down. Some of the software development roles require a lot of human intellect and creativity, which can never be replaced by a machine.
How will ML/AI change in the future?
Right now, we are limited by the processing capabilities of the current computing machines. In the status quo, the processing machines are deterministic i.e given an input, the result can be determined. We are trying to use this machine in order to model a system that is highly probabilistic in nature. I think, in another decade or so, we would come up with an entirely new architecture of computing, that would be probabilistic, instead of the deterministic nature of current processors. This would signal a huge leap in the ML/AI space as a probabilistic machine can better represent a human who has never been a deterministic being.
17 Feb 2017
Why would anyone want to be a Machine Learning engineer?
I cannot be presumptuous and speak for others, but I can tell you why I wanted to be one. It boils down to one word. "Magic".
It all goes back to my childhood when I was utterly bitten by the computer bug in my father's office. I used to hang out with him most of the days, playing games on the computer. I was enthralled by the possibility of such a small machine that makes the tiny human on the screen jump when I press a button. How does that piece of metal know what to do and when? And it was capable of running not one, but multiple games! I could ride a bike, kick another person while riding a bike, I could race cars, I could rescue a princess, I could go through prison walls. Imagine your fantasy world being given to you in a small piece of metal box to do with as you please. It was magic to a 5 year old.
The intense curiosity fuelled by a magic trick and the drive to find out how it was being pulled off is what captured my fascination in computers.
Result: I was simple boy. I just wanted to know how it worked.
Fast forward 12 years, I am a CS student at an engineering college, learning how a computer does what it does. After learning a bit about computers and coding in high school, you now understand how a computer runs your game, how it calculates the equations you throw at it and how it is capable of a myriad of operations that you didn't know existed. Your curiosity is quenched up to a certain extent. A computer is not that much of a magic box that it once seemed to be. All is good.
Then you encounter a computer that can recognize your voice and can convert your speech to text! And your entire understanding of how a computer works is turned upside down. If you ask it to add 4 and 5, you know it is capable of giving you the correct answer. But you give it an audio file and ask it to recognize it, you would never expect it to actual deliver. Add the fact that the underlying architecture of a computer has not changed in decades, the ability of a computer to take such soft, ambiguous decisions based on just algorithms is mind blowing.
It seems like magic when I see a computer recognizing my face in a video, recognizing my friends in the picture, gauging my emotions, hailing a cab when it's time to leave for office and asking if I wanted a coffee on the go since it understands that I love coffee and take it usually in the mornings. It was magic to a 20 year old.
Being exposed to this all new ability of computers to affect our daily lives and change it drastically for the better (or worse) just fuels my curiosity further. How does it know where to park the car? How does it know if I am going to the office or to my friend's place?
Even after 4 years of studying CS, a computer can still make you drop your jaw, just like it did when you were 5 years old. It still appears to be a magic box that is capable of doing something you would never expect it to do.
Result: I am a simple man. I just want to know how it works. Plain and simple.