
Reducing Model Size - Language Models
24 Apr 2020The size of the SOTA neural networks is growing bigger everyday. Most of the SOTA models have parameters in excess of 1 billion.
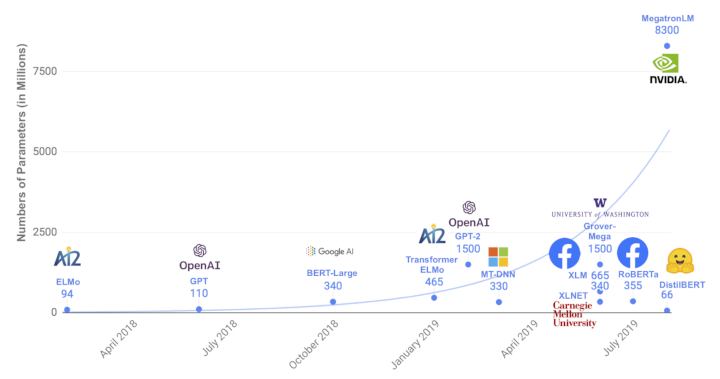
The above image is taken from Huggingface’s DistilBERT
This trend has multiple effects on NLP research:
1. NLP leaderboards are dominated by results from industry, who have access to the vast compute and data resources required to train these humongous models. Companies are incentivized to keep this research proprietary, at least part of it to maintain intellectual superiority among competitors. Open research from the academia is unable to keep up.
2. Larger model sizes preclude deploying on mobile devices.
3. Large compute resources are required to even run inferences on these models. This compute requires energy, which in turn leaves a bigger carbon footprint.
4. The notion (and proof) that bigger always outperforms a smaller model has inspired researchers to build bigger and bigger models instead of other paradigm shifting ventures. As Francois Chollet puts it, “Training ever bigger convnets and LSTMs on ever bigger datasets nets us closer to strong AI – in the same sense that building taller towers brings us closer to the moon”.
Given these issues, this blog post summarizes the current efforts and research in the direction of reducing model footprints.
1. Neural Networks are over-parameterized
Ramanujan, Vivek et al. “What’s Hidden in a Randomly Weighted Neural Network?” proposes that even before train a neural network, a randomly initialized neural network already consists of sub-networks that can perform almost as well as a fully trained model. They also propose an algorithm to identify these sub-networks.
2. Distillation
This is a teacher-student architecture, where a bigger model (teacher)’s outputs/hidden activations are used to train a smaller model (student). This has been applied generally to many neural models. For BERT specifically, Huggingface’s DistilBERT, is a good resource with implementation. The output of the bigger BERT model and the output of the smaller model are used to calculate the cross-entropy loss (with or wothout temperature).
SOTA in distillation is TinyBERT. They propose a novel distillation procedure optimised for transformer based networks (which BERT is). Unlike DistilBERT, where only the softmax output is used to train the student, TinyBERT uses the hidden activations including the attention weight matrices to train the student.
3. Pruning
Here, we focus on reducing the model size by either removing transformer heads, weights themselves or by removing layers.
Elena Voita et al. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned propose removing the attentions heads from the transformer. Similar efforts is proposed by Paul Michel et al. in Are Sixteen Heads Really Better than One?. They propose a Head Importance Score (a differentiation of loss w.r.t the head activation) as a measure to prune heads. Results suggest that we can remove almost 60-80% of the heads without much impact on the performance.
Ziheng Wang et al. Structured Pruning of Large Language Models propose a way to remove model weights.
Angela Fan et al. Reducing Transformer Depth on Demand with Structured Dropout propose a way to remove model layers by using a method similar to dropouts. Unlike dropouts, where certain model parameters are frozen during training, they propose freezing certain layers while training. This lends the model to having some layers to be able to be removed and not affect the performance significantly.
4. Quantization
Another approach to reduction in model sizes is to convert the floating point numbers representing the model parameters into integers. Intel’s Q8BERT is one of the implementations of this approach.